Last week has been a series of big releases as far as the Agile world goes. We got the new SCRUM guide, 2020 State of DevOps Report from Puppet and Gartner Hype Cycle for Artificial Intelligence, 2020.
While I was going through all of them like a Kid in the candy store, trying to understand the differences from last year. My keen eye kept comparing the previous versions also to catch any anomalies. While I was doing that I realized one of the key challenges that the technology companies were facing.
We are making the DevOps and Agile world too complicated. There is already a big enough set of To-Do’s that the teams have to adhere to while they are sprinting ahead in full speed. How on earth are the teams and leaders going to keep up with the fast changing terms and techniques. Worse, new patterns and anti-patterns.
After thinking hard and fast about this conundrum, I have decided that I will write a blog on the basic of DevOps. A bare minimum DevOps that teams can take up if you are wondering how to get started! This is my attempt at it. Please share your thoughts around the same.
History of DevOps
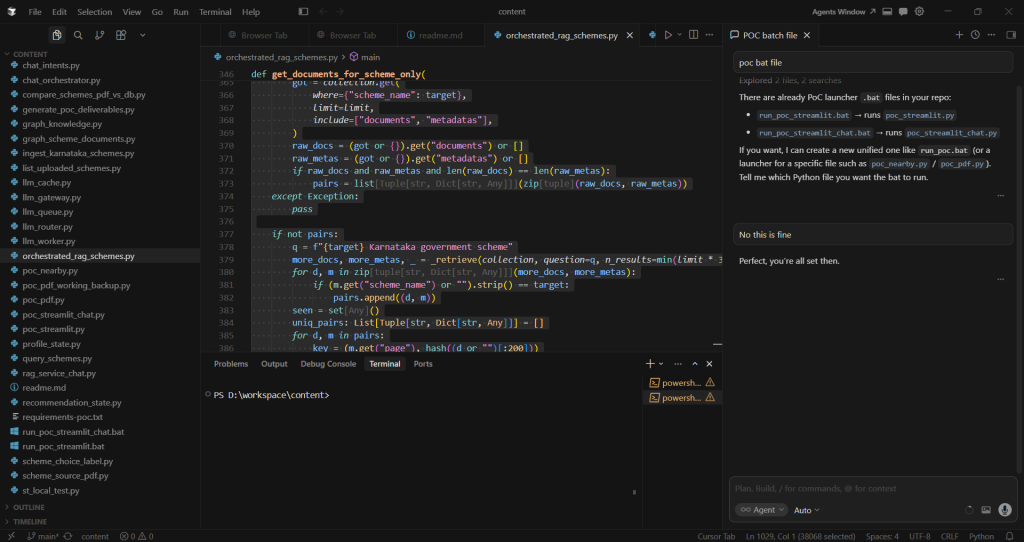
While we tackle DevOps, I wanted to share a picture that was released in the year 2009 while the term DevOps was going to be coined by Patrick Debois from Belgium and Andrew “Clay” Shafer coined the term “DevOps”.
Ref: http://www.jedi.be/blog/2009/12/22/charting-out-devops-ideas/
The above pic was the set of ideas that the entire DevOps was based on. As you can see from various loops that are present, DevOps is all about the BIG feedback loop and how quickly can you traverse in the loop and looking at all the stakeholders.
Definition of DevOps
Now that we have the history of DevOps nicely laid out, lets talk about definition. I know that there is really now need. This is from the Authority of DevOps by Gene Kim from the “The Phoenix Project”

If we look at the clear benefits that are accrued they are quite a few. Headline benefits comes down to the 4 steps
- Increasing need for innovation on the systems side of technology work
- Need for increase in feedback loops between business, all parts of the delivery process and operations
- Increase the quality of software by increase in feedback loops
- Increase in the speed up the flow
Coming to think of it, now, there are many organizations that often talk about DevOps movement or a product driven culture to Digital Transformation. And that is definitely a story for a different day.
As I promised, I will stay with what does it mean to be DevOps.
Architecture Features of DevOps
Any DevOps implementation at the product or product line or enterprise level need three critical features
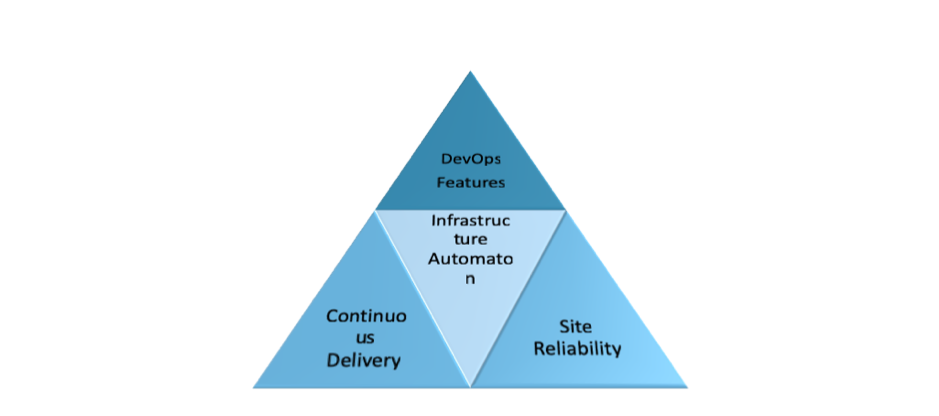
Often times we speak only about the Continuous Delivery and in case of cloud implementation – Site reliability. The foundational element of Infrastructure Automation is equally critical.
- Continuous Delivery – Build, test, deploy your apps in an automated manner using pipelines, scripting and higher confidence and faster
- Infrastructure Automation – Create your systems, configs, and app deployments in a way that all the environments mimic the production
- Site Reliability Engineering – operate your systems; monitoring and orchestration, sure, but also designing for operability in the first place
I am taking each part and sharing some example implementation to throw some light
Infrastructure Automation
Infrastructure automation is also known by several names configuration management, IT management, Provisioning, scripted infrastructures and system configuration management. Used to be referred as Infrastructure as a Code – IaC
Infrastructure automation is the process of scripting environments
- installing an operating system
- installing and configuring servers on instances
- configuring how the instances and software communicate with one another
By scripting environments, you can apply the same configuration to a single node or to thousands. This configuration is also used in setting up dev environments till the performance environment.
Few years back, for a project, I had partnered with a colleague of mine to create Ansible script to develop the dev environment. The rest of the team had already started working on the sprint 1 stories and as a Program Lead, my predicament was two fold
- We are taking too long in setting up the dev environment
- We are giving up functional stories from completing
It took two entire sprints to setup the components required to setup the automated dev environment. In the process, we uncovered several issues and sharing some of the benefits
- Different team members were using varied versions of Java. There was no problem that was found at that point. But I can imagine it becoming a problem later
- We expanded the team by 4 new members, it took exactly 1 hour to setup their environments instead of the usual 2 days. Best part was that, during that 1 hour, the 4 new members were going through the product backlog!!
- Client members started using the same script to setup the test environments with a few configuration changes
While it is very tempting for leaders to prioritize or possibly stop doing infrastructure automation as benefits would only accrue over a period of time. But when it starts accruing it would be exponential in nature.
Most popular open source infrastructure automation tools: Chef, Ansible and Puppet
Continuous Delivery
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way.
Principles of Continuous Delivery can be encapsulated in only 6 key thinking models. These are in line with the agile principles also if you keenly observe!
- Delivery are Build quality in
- Work in small batches
- Computers perform repetitive tasks
- people solve problems
- Relentlessly pursue continuous improvement
- Everyone is responsible
Patterns that I have been fascinated of is available here. When in doubt, this has been my go-to destination.
Some of my learnings in applying them in my product teams are below
- Plan to include continuous integration in all the sprints.
- Unit test automation as part of the DoD
- Automate critical scenarios (100% coverage will stay as a mirage)
- Packaging for production need to be from the main trunk
- Fix Build as soon as it fails and possibly create visual build boards
- Fix Test scenarios as soon as it fails and possibly create visual build boards
- Treat test data and scripts as code
These simple 7 steps are all that’s required to get the teams started in the continuous delivery journey. The #4 is the hardest as there is always temptation to go to feature based branching. You can refer to my blog on Test automation here.
Site Reliability Engineering
This is really the newest field in DevOps and most talked about. It covers all the non-functional requirements *ities – Like Security, performance/scalability, auditability,
It has been popularized by Google. In a nutshell, SRE is “what happens when a software engineer is tasked with what used to be called operations.”[2]
Tools such as Kubernetes has made SRE popular and many organizations that I am working with have started recruiting or creating roles for SREs.
I have limited experience in the area while I coached one SRE teams on Agile basics. I would call myself a learner in this area and hence leaving with you only at a starting point.
3 Reflections of the State of DevOps 2020
My reflections of the State of DevOps are that while I talk to the GAFAM or FAANG companies, there is a sense that DevOps has been entrenched in the companies psyche. However, when I look at the state of DevOps, data is saying something different. When teams and coaches try to discuss DevOps, there is already an uphill task to achieve in the minds of stakeholders. While we often talk about the best runner in the world and that’s what gets most screen time. Its critical for everyone to think from a culture and improvement on a year or year basis. Its useful to look at what is required in the respective business context.
In 2018, 10% of the companies have been in the High level of DevOps adoption and needle has moved extremely slowly to a number of 16% only. That was a big surprise for me. More I reflected, I was more at peace that the DevOps journey is long and hard and most organizations are in that path. Are leaders taking the right decisions at every step of the way. I have created a Challenge of the week in the same theme
Platforms such as SRE and CD are continuing to be provided as internal platforms rather than completely part of agile teams. Critical areas that large enterprises are grappling are the fact that the skills required for DevOps is not available within the product teams and hence the team topology to stay outside the product team. In the same breadth, many of the legacy systems, are not architected with continuous delivery or SRE in mind. This create double dilemma for the product leadership.
Do they continue to invest in new features and upgrade their DevOps culture
Or
Migrate to a cloud based platform and grapple with new sets of security and reliability realities
It’s a tough choice indeed and that’s what is reflected in the State of DevOps as well. Hence senior leaders need to take the tough call between incremental upgrade to a complete migration. Both comes with its set of challenges.
Third reflection and a very surprising one at that is the change management. Orthodox companies continue to use change management for every step of the way. And having good governance helps. I always used to think that good governance structure means, automation of approvals and having rigor placed in who’s approving production releases. However this state of DevOps, has clearly, left the good governance structures only for those organizations that don’t have engineering level automation. That’s something to chew on for me!
In conclusion, DevOps Success needs to be looked at the lens of five important cultural change management – Reduce organizational silos, accept failure as normal, Implement gradual changes, Take a DevOps Toolchain and automation and most importantly Measure everything.